密码学和加密数字货币
所有货币都需要一些方法来控制供应,并强制执行各种安全属性以防止作弊。在法定货币方面,像中央银行这样的组织控制货币供应量,并对实体货币增加防伪功能。这些安全功能提高了对攻击者的防范能力,但是他们不可能不赚钱地进行伪造。最终,执法对于阻止人们违反制度规则是必要的。
加密数字货币也必须采取安全措施,防止人们篡改系统状态,并避免对不同的人造成不一致的陈述。如果Alice说服Bob,她给他一个数字货币,例如,她不应该说服卡罗尔,向卡罗尔支付同一个数字货币。与法定货币不同的是,加密货币的安全规则需要纯粹在技术上执行,而不依赖于中央机构。
顾名思义,加密货币大量使用加密技术。在加密数字货币系统本身的机制上,密码学提供了一个安全的编码规则体系。我们可以用它来防止篡改和避免模棱两可的陈述,以及将数字协议用于创建编码新货币单位的规则。在我们可以正确理解加密货币之前,我们需要深入研究密码学赖以依赖的基础。
密码学是一个深入的学术研究领域,它利用许多先进的数学技术,以巧妙而微妙的方式理解。幸运的是,比特币只依赖于一些相对简单和知名的加密结构。在本章中,我们将专门研究加密散列和数字签名,证明对构建加密货币非常有用的两个原语。未来章节将介绍更复杂的加密方案,例如零知识证明,用于比特币扩展和修改的提议。
一旦我们学习了必要的加密原语,我们将讨论一些用来构建加密货币的方式。我们将在本章中介绍一些简单的加密货币示例,演示我们需要处理的一些设计挑战。
1.1加密Hash函数
我们需要理解的第一个加密原语是加密散列函数(Hash function)。一个加密散列函数(Hash function)具有以下三个属性:
·它的输入可以是任意大小的字符串。
·它产生一个固定大小的输出。为了使本章中的讨论具体化,我们将假设它是一个256位大小的输出。然而,我们的讨论适用于任何输出大小,只要它足够大。
·这意味着对于给定的输入字符串,可以在合理的时间内计算哈希函数的输出。从技术上讲,计算一个n位字符串的散列应该有一个O(n)的运行时间。
这些属性定义了一个通用哈希函数,一个可用于构建数据结构(如哈希表)的函数。我们将专注于加密散列函数(Hash functions)。对于密码安全的哈希函数,我们将要求它具有以下三个附加属性:(1)防撞;(2)隐匿;(3)友好的谜题。
我们将更仔细地研究每一个属性,以了解为什么有这样一个函数的行为是有用的。研究密码学的读者应该意识到,本书中哈希函数的处理与标准加密教科书有点不同。特别是谜题友好的属性不是对加密哈希函数的一般要求,而是对特定加密货币的有用属性。
防碰撞性:如果不可能找到两个值x和y,使得x ≠ y,而H(x)= H(y),哈希函数H被认为是防碰撞的。
属性1:防碰撞性。我们从加密哈希函数中需要的第一个属性就是它的防碰撞。当两个不同的输入产生相同的输出时,会发生碰撞。如果没有人可以发现碰撞,哈希函数H(.)则具有防碰撞性。正式地:

图1.1哈希碰撞。x和y是不同的值,但是当输入到哈希函数H中时,它们产生相同的输出。
请注意,我们说没有人可以找到碰撞,但是我们没有说没有碰撞存在。实际上,我们确实知道碰撞存在的事实,我们可以通过一个简单的计数参数来证明这一点。哈希函数的输入空间包含所有长度的所有字符串,但输出空间只包含特定且固定长度的字符串。因为输入空间大于输出空间(实际上,输入空间是无穷大的,而输出空间是有限的),所以必须有输入字符串映射到相同的输出字符串。事实上,根据“鸽子原则”,映射到任何特定输出的可能输入必然将是非常大的。
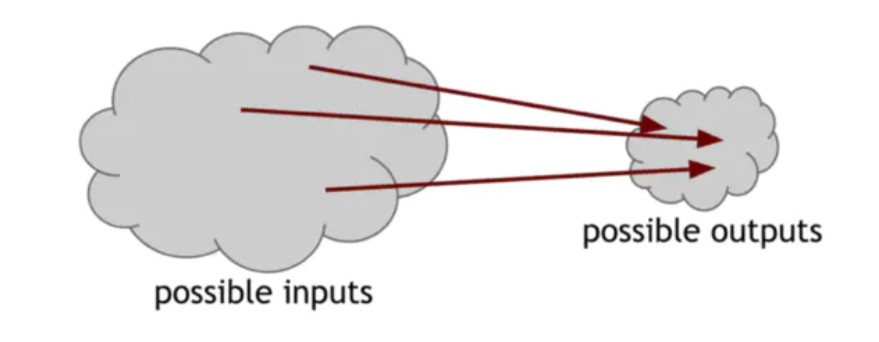
图1.2由于输入数量超过输出数量,我们保证必须至少有一个输出,能让哈希函数映射到多个输入。
现在,为了使事情变得更糟,我们说它不可能发现碰撞。然而,有些方法可以保证发现碰撞。考虑以下简单的方法来查找具有256位输出大小的哈希函数的碰撞:挑选2的256次方加1个不同的值,计算它们中每一个的hash值,并检查是否有两个一样的输出。由于我们选择了比可能输出更多的输入,所以当应用哈希函数时,它们中的一些必须发生碰撞。
上面的方法保证会找到碰撞。但是,如果我们选择随机输入并计算哈希值,那么在检查2的256次方加1个输入之前,我们会高概率的发现碰撞。事实上,如果我们随机选择2的130次方加1个输入,结果会有99.8%的概率至少有两个会碰撞。事实上,我们可以通过只是粗略地检查可能的输出数量的平方根来找到冲突,这现象在概率上被称为第二天悖论。在本章末尾家庭作业的问题中,我们将对此进行更详细的研究。
这种碰撞检测算法适用于每个哈希函数。但是,问题在于这需要很长很长的时间。对于具有256位输出的哈希函数,在最坏的情况下,您必须计算哈希函数2的256次方加1次,平均大约2的128次方次。这当然是一个天文数字 ——如果一台计算机每秒计算10,000次hash值,那么需要超过一千万(10的27次方)年的时间来计算2的128次方个hash值!以另一方式来思考这个问题,我们可以这样说,如果人类制造的每一台计算机从宇宙诞生以来都开始计算,到目前为止,他们发现冲突的几率仍然是非常渺小的。如此之小,比地球在接下来的两秒钟内被一颗巨大的流星摧毁的几率都要小得多。
因此,我们看到了一种通用但不切实际的算法来找寻任意哈希函数的碰撞。一个更难的问题是:是否有其他方法可以在特定的哈希函数上使用,以便找到碰撞?换句话说,虽然通用碰撞检测算法是不可行的,但仍然可能有其他一些可以有效地找到特定哈希函数碰撞的算法。
例如,考虑以下哈希函数:

该函数满足我们对散列函数的要求,因为它接受任何长度的输入,返回一个固定大小的输出(256位),并且是有效可计算的。这个函数还有一个找到碰撞的有效方法。请注意,此函数只返回输入的最后256位。一个碰撞的值会是3和3加2的256次方。这个简单的例子说明,尽管我们的通用碰撞检测方法在实践中是不可用的,但至少存在一些确实有效的碰撞检测方法的哈希函数。
然而对于其他哈希函数,我们不知道是否存在这样的方法。我们怀疑他们是抗碰撞的。但是,没有任何哈希函数被证明是抗碰撞的。我们在实践中依赖的加密哈希函数只是人们尝试的功能,真的很难找到碰撞,且从未成功过。在某些情况下,如旧的MD5哈希函数,最终在多年的工作中发现了冲突,导致功能过时,被实用界逐步抛弃。所以我们选择相信那些是抗碰撞的。
应用:消息摘要现在我们知道抗碰撞是什么,合乎逻辑的问题是:抗碰撞有什么用?这里有一个应用:这里有一个应用:如果我们知道抗碰撞哈希函数H的两个输入x和y是不同的,那么可以安全地假定它们的hash值H(x)和H(y)是不同的,如果有人知道一个x和y是不同的,但是具有相同的hash值,这将违反我们的假设,这样的H是抗碰撞的。
这个论据允许我们使用hash输出作为消息摘要。考虑SecureBox,一个经过身份验证的在线文件存储系统,允许用户在下载文件时上传文件并确保其完整性。假设Alice上传的文件很大,想要稍后能验证她下载的文件与上传的文件是一样的。一种方法是在将整个大文件保存在本地,并直接将其与下载的文件进行比较。虽然这样做有效,但它在很大程度上违背了上传它的目的;如果Alice需要访问文件的本地副本以确保其完整性,则可以直接使用本地副本。
无碰撞的哈希为这个问题提供了一个优雅而高效的解决方案。Alice只需要记住原始文件的hash值。当她以后从SecureBox下载文件时,她会计算下载的文件的hash值并将其与存储的文件进行比较。如果哈希值是相同的,那么她可以得出结论,文件确实是她上传的,如果它们不同,那么Alice可以断定该文件已被篡改。因此,记住哈希可以让她在传输过程中或在SecureBox的服务器上检测文件的意外损坏,而且还可以由服务器义务修改文件。面对其他实体潜在的恶意行为,这是加密技术为我们提供保证的核心。
Hash用作消息的固定长度摘要或明确的摘要。这给了我们以一个非常有效的方式来记住我们以前看到的事情,并再次认出它们。而整个文件可能已经是千兆字节长,hash却是固定的长度,在我们的例子中hash函数有256位字节。这大大降低了我们的存储需求。在本章后面和整本书中,我们将看到使用哈希作为消息摘要的有用应用程序。
属性2:隐匿性从哈希函数中得到想要的第二个属性是隐匿。隐匿属性声明如果我们给出hash函数y= H(x)的输出,则没有可行的方法来确定输入x是什么。问题是,该属性不能以声明的形式存在。考虑以下简单的例子:我们要做一个掷硬币的实验。如果硬币翻转的结果是头,我们要宣布字符串的哈希值是“头”。如果结果是尾,那么我们要宣布字符串的哈希值是“尾”。
然后我们问一个没有看到硬币翻转,只看到哈希输出值的对手,让他弄清楚字符串是散列的(我们很快就会知道为什么我们可能想玩这样的游戏)。作为回应,他们将简单地计算字符串“头”和字符串“尾”的哈希值,并且他们可以看到他们被给予了哪一个。所以,在短短几步之后,他们可以弄清楚输入的是什么。
对手能够猜出这个字符串是因为x只有两个可能的值,对手很容易尝试这两个值。为了能够实现隐匿属性,需要注意的是没有特别可能的x值,也就是说x必须在某种意义上从分散的集合中选择。如果从这样一个集合中选择x,那么尝试x值可能有几个值的方法将不起作用。
最大的问题是:当我们想要的值不像我们的“头”和“尾”的实验那样,我们可以实现隐匿的属性吗?幸运的是,答案是肯定的!所以我们或许可以隐藏,甚至一个输入可以不通过将其连接到另一个相关联的输入来传播。我们现在可以稍微更精确地说明我们隐匿的意思(双垂直条‖表示连接)。
隐匿 hash函数H是隐匿的,如果:从具有高的最小熵的概率分布中选择秘密值r,当给定H(r||x)时,找到x是不可行的。
在信息理论中,最小熵是衡量结果可预测性的一个指标,高最小熵捕捉到分布(即随机变量)是非常分散的直观思想。这具体意味着,当我们从分布中抽样时,没有特定的值可能发生。所以,对于一个具体的例子,如果从256位长的所有字符串中均匀地选择了r,然后选择任何特定的字符串的概率为1/2的256次方,这是一个无穷小的值。
应用:托管现在让我们来看一下隐匿属性的应用。特别是我们想要做的就是所谓的托管。托管的是带有值的数字模拟,把它密封在一个信封里,然后把信封放在桌子上,每个人都可以看到它。当你这样做时,你已经托管了信封里面的内容。但是你没有打开它,所以即使你托管了一个值,这个值对于其他人仍然是秘密。稍后,你可以打开信封并显示你先前提交的值。
托管方案托管方案由两种算法组成:
com:=托管(msg,nonce)托管函数输入消息和秘密的随机值nonce,返回一个托管值
校验(com,msg,nonce)验证函数将托管值、随机数nonce和消息作为输入。如果com==commit(msg,nonce)则返回True,否则返回False。
我们要求以下两个安全属性保持不变:
隐匿:给定com,找到msg是不可能的。
绑定:不可能找到两对(msg,nonce)和(msg’,nonce’),这样msg≠msg’但commit(msg,nonce)==commit(msg’,nonce’)
要使用托管方案,我们首先需要生成随机数n。然后,我们将commit函数与msg一起应用到该随机数n,该值被托管,并发布托管值com。这个阶段类似于将密封的信封放在桌子上。稍后,如果我们想要揭示他们之前提交的值,我们会发布我们用来创建这个托管的随机数n,以及消息msg。现在,任何人都可以验证msg确实是早期托管的消息。这个阶段类似于打开信封。
每次你托管一个值,重要的是您选择一个新的随机数n。 在密码学中,术语“随机数”用于指代只能使用一次的值。
这两个安全属性规定,算法实际上表现为密封和打开信封。首先,给定com和托管,只看信封的人无法弄清楚里面的信息是什么。第二个属性是它的绑定。这样可以确保当你托管信封中的内容时,你将不能再改变主意。也就是说,找到两条不同的消息是不可行的,你不可以提交一个消息,然后再声明你已经提交另一个消息。
那么,我们怎么知道这两个属性呢?在我们回答之前,我们需要讨论如何实际实施一个托管方案。我们可以使用加密哈希函数来做到这一点。考虑以下托管方案:
commit(msg, nonce) := H(nonce ‖msg) n是一个256字节的随机数
为了提交一个消息,我们生成一个256位的随机数n。然后我们连接随机数n和消息,并返回这个连接值的哈希作为托管。要验证,有人要去计算与消息连接的随机数的相同哈希值。他们会检查这是否等于他们看到的托管。
再看一下我们承诺计划中需要的两个属性。如果我们替换实例化的托管,然后验证H(nonce||msg)是com,那么这些属性将变为:
隐匿:给定H(nonce||msg),不可能找到msg
绑定:不可能找到两对(msg,nonce)和(msg’,nonce’),这样msg≠msg’但H(msg,nonce)==H(msg’,nonce’)
托管的隐匿属性正是我们对哈希函数所需的隐匿属性。如果密钥被选择为256位的随机值,则隐匿属性表示,如果我们对密钥和消息一起进行哈希,那么从哈希的结果去恢复消息是不可能的。事实证明,绑定属性隐含了底层哈希函数的抗碰撞特性。如果哈希函数是抗碰撞的,那么是不可能找到不同的msg和msg'的,使得H(nonce‖msg)= H(nonce’||“msg”),因为这些值确实是一个碰撞。
因此,如果H是具有防碰撞和隐匿的哈希函数,则该托管方案将在其具有必要的安全属性的意义上起作用。
属性3:谜题友好性我们从哈希函数中需要的第三个安全属性是谜题友好。这个属性有点复杂。首先,我们将解释这个属性的技术要求,然后给出一个应用程序,说明为什么这个属性是有用的。
谜题友好 一个哈希函数H被称为谜题友好——对于每个可能的n位输出值y,如果从具有高最小熵的分布中选择k,则不可能找到x使得H(k||x)=y最后明显小于2的n次方。
直观地说,这意味着如果有人想要将哈希函数定位到一些特定的输出值y,那么如果有一部分输入以适当的随机方式选择,则很难找到另一个值恰好命中该值。
应用:搜索谜题现在,我们通过一个应用来说明这个属性的有用性。在这个应用中,我们将构建一个搜索谜题,一个需要搜索非常大空间才能找到解决方案的数学问题。特别的是,这个搜索谜题没有捷径。也就是说,除了穷尽整个空间之外,没有办法找到有效的解决方案。
搜索谜题 搜索谜题包括
·一个哈希函数,H
·一个值,id(我们称之为谜题ID),从高最小熵分布中选择的
·目标集合Y
这个谜题的解决方案是一个值x,使得
H(id‖x)∈Y.
直觉是这样的:如果H具有n位输出,则可能是2的n次方个值中的任何一个。如果要解决谜题,需要找到一个输入,使得输出落在远小于所有输出集合的集合Y内。Y的大小决定了谜题的难度。如果Y是所有n位串的集合,这个谜题是微不足道的,而如果Y只有1个元素,那么这个难题就是最难的。谜题ID具有高的最小熵的事实,确保这没有捷径。相反,如果ID的特定值很适合,那么有人就可能会欺骗,比如通过使用该ID预先计算一个谜题的解决方案。
如果一个搜索谜题是谜题友好的,这意味着这个谜题没有解决策略,这比只是尝试x的随机值更好。因此,如果我们想要构建一个难以解决的谜题,只要我们能以适当的随机方式生成谜题ID就可以了。稍后当我们谈论比特币开采时,我们将使用这个想法,这是一种计算谜题。
SHA‐256。我们已经讨论了哈希函数的三个属性,并且每个属性都有一个应用实例。现在,让我们来讨论一个将在本书中使用很多次的特定哈希函数。哈希函数有很多,但是这个是Bitcoin主要使用的,一个相当不错的使用。这就是所谓的SHA-256。
回想一下,我们要求哈希函数适用于任意输入长度。幸运的是,只要我们可以建立一个适用于固定输入长度的哈希函数,用一个通用的方法将其转换成适用于任意输入长度的哈希函数即可。这就是所谓的Merkle‐Damgard转换。SHA‐256是使用这种方法的常用哈希函数之一。在通用术语中,底层为固定长度抗碰撞哈希函数被称作压缩函数。已经证明,如果底层压缩函数是抗冲击的,那么整个哈希函数也具有抗冲击性。
Merkle‐Damgard转换非常简单。说的是压缩函数取长度为m的输入,并产生一个较小长度为n的输出。对哈希函数的输入,可以是任何规模,被分成长度为m-n的块。结构工作如下:将每个块与前一块的输出一起传递到压缩函数。注意,输入长度将变为(m-n)+n=m,这也是压缩函数的输入长度。对于没有先前块输出的第一个块,我改为使用初始化向量(IV)。这个数字被重复使用到哈希函数的每一个调用中,实际上你可以在标准文档中查找到。最后一个块的输出就是你想要返回的结果。
SHA-256采用一个压缩函数,它需要768位输入并产生256位的输出,块的大小为512位。有关SHA-256工作的图形说明,请参见图1.3。
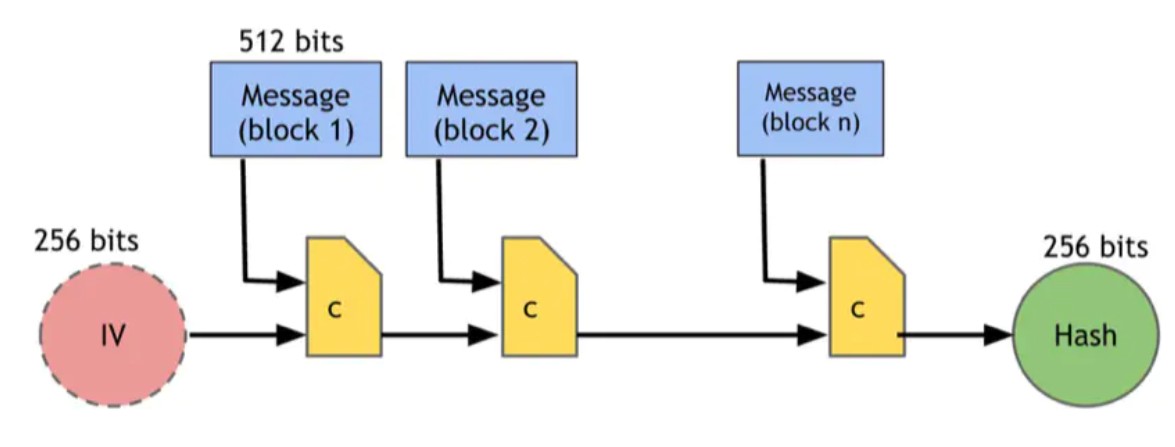
图1.3:SHA-256哈希函数(简图)SHA‐256使用Merkle-Damgard变换将固定长度的抗碰撞压缩函数转换为接受任意长度输入的哈希函数。它的输入是“填充”,故其长度为512位的倍数。
我们讨论了哈希函数,具有特殊属性的加密哈希函数,这些属性的应用以及我们在比特币中使用的特定哈希函数。在下一届中,我们将讨论如何使用哈希函数来构建更多复杂的数据结构,这些数据结构用于像Bitcoin这样的分布式系统。
补充部分:哈希函数建模哈希函数是加密领域的瑞士军刀:他们在各种各样的应用中找到了一个地方。这种多功能性的另一面是,不同的应用需要稍微不同的哈希函数属性来确保安全性。众所周知,很难确定一个哈希函数属性的列表,这将导致整个系统的安全性证明。
在本文中,我们选择了三中属性,这些属性对于比特币和其他加密货币使用哈希函数的方式至关重要。即使在这个空间中,并不是所有这些属性都是每次使用哈希函数所必需的。例如,我们将看到谜题友好只在比特币挖矿中是重要的。
安全系统的设计者通常会抛出一个模型,将哈希函数建模为为每一个可能的输入输出独立随机值的函数。在密码学中,使用这种“随机语言模型”来证明安全性仍然存在争议。不管人们对这个辩论的立场如何,论证如何将我们的应用中所需的安全属性降低到底层基元的基本属性上,对于构建安全系统是一个很有价值的智力练习。我们在本章中的陈述旨在帮助你学习这项技能。
1.2哈希指针和数据结构
我在本节中,我们将讨论哈希指针以及它的应用。哈希指针是一种数据结构,它在我们将讨论的许多系统中非常有用。哈希指针只是一个指向一些信息与利用加密哈希的信息存储在一起的指针。一个常规指针给你一种检索信息的方法,而一个哈希指针也提供了一种验证信息没有改变的方法。

图1.4:哈希指针S哈希指针是一个指向数据在某个固定时间点与该数据的加密哈希值一起存储的位置指针。
我们可以使用哈希指针来构建各种数据结构。直观地,我们可以采用一种熟悉的数据结构,它使用诸如链接列表或二叉搜索树之类的指针,并用哈希指针来实现,而不是像通常那样使用指针。
区块链在图1.5中,我们使用哈希指针构建了一个链表。我们将把这个数据结构称为区块链。而在具有一系列块的常规链表中,每个块都有数据,以及指向列表中先前一个块的指针,在块链中,前一个块指针将被替换为哈希指针。因此,每个块不仅告诉我们上一块的值在哪里,而且还包含该值的摘要,允许我们验证值没有改变。我们存储列表的头,它只是一个指向最新数据块的常规哈希指针。
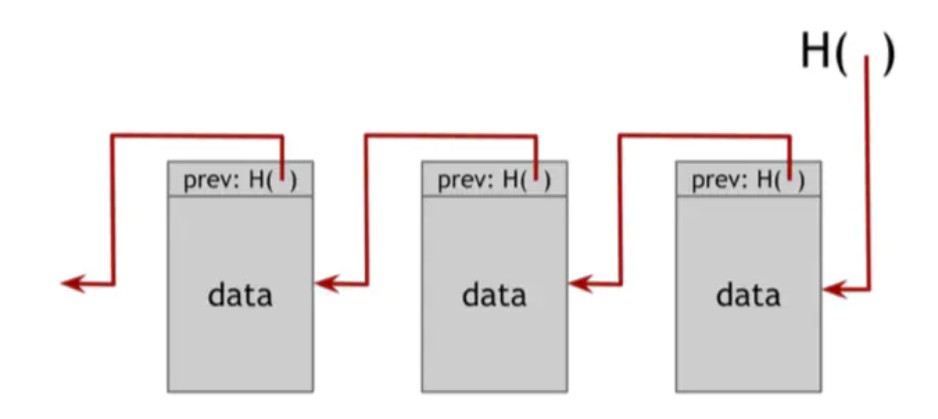
图1.5区块链 区块链是一个使用哈希指针而不是指针构建的链表。
区块链的一个用例就是一个防篡改的日志。也就是说,我们要构建一个存储一堆数据的日志数据结构,并允许我们将数据附加到日志的末尾。但是,如果有人改变了日志中较早的数据,我们将会检测到它。
要了解为什么一个区块链可以实现这个篡改的属性,让我们来看一看,如果对手想篡改链中间的数据会发生什么。具体来说,对手的目标是以这样的方式进行的,只记住区块链头部的哈希指针的人将无法检测到篡改。为了实现这个目标,对手改变了一些区块k的数据。由于数据已经被改变,区块k+1中的哈希值是整个区块k的哈希值,因此不会匹配。请记住,我们在统计上保证,由于哈希函数具有抗碰撞性,故新哈希将不会与更改后的内容相匹配。因此,我们将检测区块k中的新数据与区块k+1中的哈希指针之间的不一致。当然,对手可以继续尝试通过改变下一个区块的哈希来掩盖这个变化。对手可以继续这样做,但是当他到达名单的头部时,这个策略就会失败。具体来说,只要我们将哈希指针列表的头部存储在对手不能改变的地方,对手将不能在不被检测的情况下改变任何区块。
这样做的结果是,如果对手想要在整个链中的任何地方篡改数据,为了保持故事的一致性,他将不得不篡改哈希指针直到它开始的地方。而且他最终会遇到障碍,因为他无法篡改列表的头部。因此出现的是,通过记住这个单独的哈希指针,我们基本上记住了一个防篡改哈希的整个列表。因此,我们可以构建一个像这样的区块链,它包含了我们想要的区块,在列表的开始追溯到的一些特殊的区块,我们将其称之为起源区块。
您可能已经注意到,这个区块链结构类似于上一节中我们看到的Merkle-Damgard结构。实际上,它们是非常相似的,同样的安全论据也适用于他们。
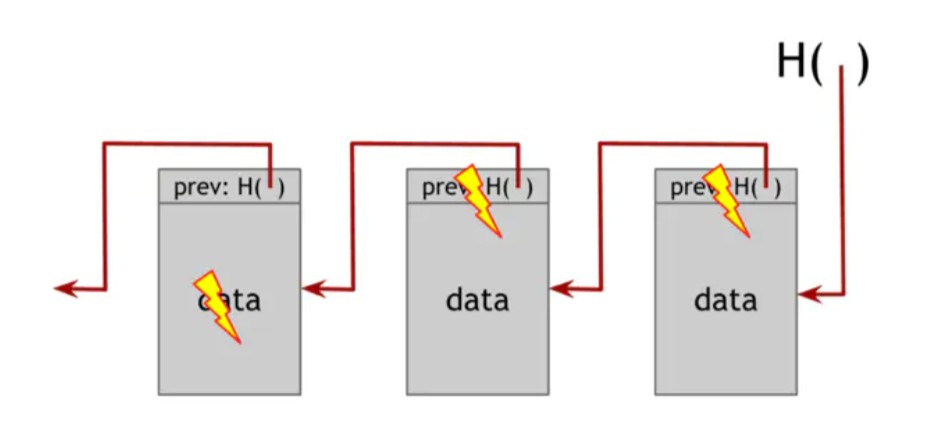
图1.6防篡改日志 如果对手在区块链中的任何位置修改数据,则会导致以下区块中的哈希指针不正确。如果我们存储列表的头部,那么即使对手将所有指针修改为与修改后的数据一致,头指针也将不正确,我们会检测到篡改。
Merkle树。我们可以使用哈希指针构建的另一个有用的数据结构是二叉树。具有哈希指针的二进制树被称为Merkle树,其发明人是Ralph Merkle。假设我们有一些包含数据的区块,这些区块包括我们树的叶子。我们将这些数据块分成两组,然后对于每一对,我们构建一个具有两个哈希指针的数据结构,每个指向其中之一的区块。这些数据结构成为树的下一个级别。我们反过来将它们分成两组,每对都创建一个包含每个哈希的新数据结构。我们继续这样做,直到我们到达一个单一的区块,树的根。
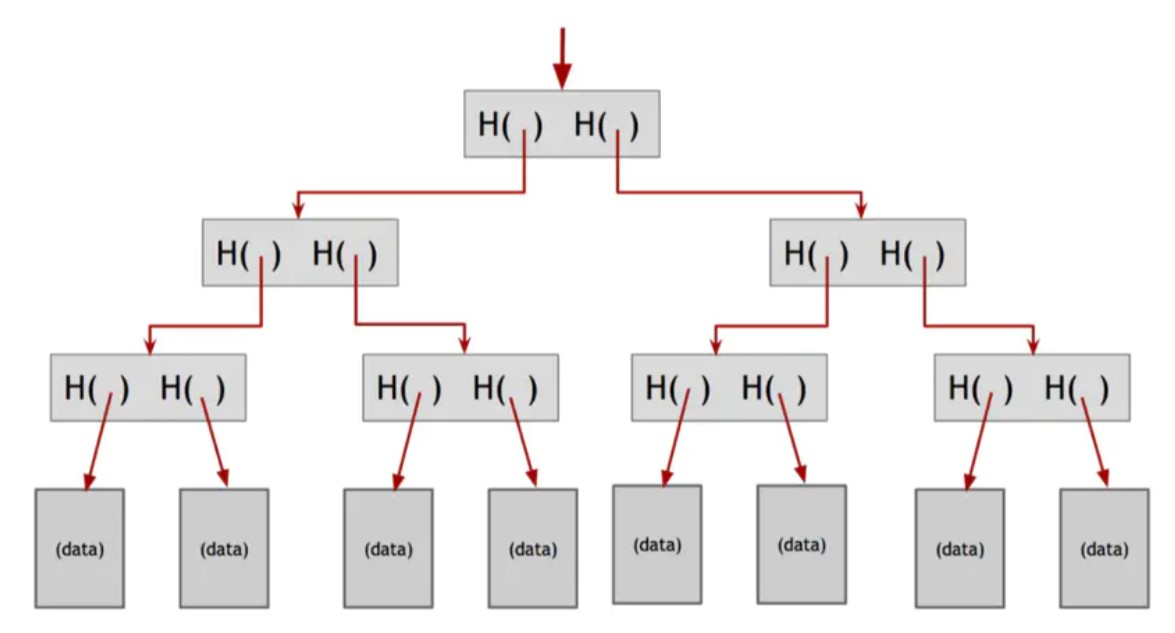
图1.7 Merkle树 在Merkle树中,数据块成对分组,并且这些块中的每一个的哈希存储在父节点中。父节点依次成对分组,并将其哈希存储在树的上一级。这一直延续到树上,直到我们到达根节点。
像以前一样,我们只记得树的头部的哈希指针。我们现在有能力向下遍历哈希指针到列表中的任何一点。这样我们就可以确保数据没有被篡改,因为正如我们用区块链所看到的那样,如果一个对手在树底部篡改一些数据块,这将导致一个级别的哈希指针不匹配,即使他继续篡改该区块,更改将最终传播到树的顶部,在那里他将无法篡改我们存储的哈希指针。再来一次,任何篡改任何数据的尝试都将通过记住顶部的哈希指针来被检测。
会籍证明Merkle树的另一个很好的特征是,与之前建立的区块链不同,它允许一个简明的会籍证明。有人想证明某个数据块是Merkle Tree的成员。像往常一样,我们只记得根源。然后他们需要向我们显示这个数据区块,以及从数据区块到根的路径上的区块。我们可以忽略树的其余部分,因为该路径上的块足以允许我们一直验证散列到树的根部。有关如何工作的图形描述,请参见图1.8。
如果树中有n个节点,则只需要显示大约log(n)个项目。并且由于每个步骤只需要计算子块的哈希值,所以需要大约log(n)时间来验证它。所以即使Merkle树包含了大量的块,我们仍然可以在相对较短的时间内证明成员资格。验证因此在时间和空间上运行,数目是树中节点数的对数。
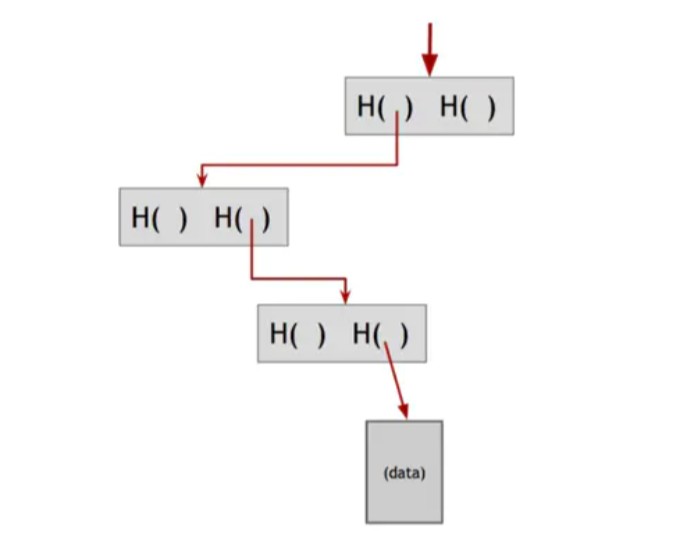
图1.8会籍证明 为了证明树中包含一个数据块,只需要显示从该数据区块到根的路径中的区块。
一个分类的Merkle树只是一个我们在底部采集区块,使用一些排序函数进行排序的Merkle树。这可以是字母顺序,字典顺序,数字顺序或其他一些约定的顺序。
非会籍证明Merkle树的另一个很好的特征是,与之前建立的区块链不同,它允许一个简明的会籍证明。
使用排序的Merkle树,我们可以在时间和空间的对数上验证非会员资格。也就是说,我们可以证明一个特定的区块不在Merkle树中 。而我们这样做的方式只是简单通过显示一个项目的路径,这个项目恰好在所讨论项目之前,并显示该项目的路径。如果这两个项目在树中是连续的,那么这可以作为证明该项目不包括在内的证据。因为如果它被包括,它将需要在显示的两个项目之间,但因为它们是连续的,故它们之间没有空格。
我们已经讨论过在链表和二叉树中使用哈希指针,但更普遍的是,只要数据结构没有循环,我们就可以在任何基于指针的数据结构中使用哈希指针。如果数据结构中有循环,那么我们将无法使所有的哈希值相匹配。如果你考虑一下,在一个非循环的数据结构中,我们可以在叶子附近开始,或者靠近没有任何指针出来的东西,计算它们的哈希值,然后回到起始点。但是在一个有循环的结构中,没有一个地方是头,也没有一个地方是尾,我们无法从头开始并从中计算出来。
所以,考虑到另一个例子,我们可以从哈希指针中构建一个有向无环图。我们将能够非常有效地验证该图表中的成员资格,而且它很容易计算。以这种方式使用哈希指针是一般的技巧,您将在分布式数据结构和本章后面的整个本书中讨论的算法中一次又一次地看到。
1.3数字签名
在本节中,我们将看看数字签名。这是第二个加密原语,和哈希函数一样,我们后续会把它作为加密的构建区块来讨论。数字签名应该是手写在纸上签名的模拟数字。我们希望数字签名中的两个属性与手写签名类比很好。首先,只有你可以签名,但任何看到它的人都可以验证它是否有效。其次,我们希望将签名与特定文件相关联,以便签名不能用于表示你的协议或认可其他文档。对于手写签名,后一个属性类似于确保有人不能将您的签名从一个文档中删除,并将其粘贴到另一个文档的底部。
数字签名方案数字签名方案由以下三种算法组成:
·(sk,pk):=generateKeys(keysize)The generateeys的方法获取一个密钥的大小,并生成一个密钥与之配对。秘密密钥sk被保密起来,用于签署消息。Pk是你向每个人提供的公开验证密钥,任何拥有此密钥的人都可以验证你的签名。
·sig:=sign(sk,message)符号方法将消一个消息和一个秘密密钥sk作为输入,并在sk下输出签名消息
·isValid:=verify(pk,message,sig)验证方法将消息、签名和公钥作为输入。它返回一个布尔值isValid,如果sig是公钥pk下的有效签名消息则为true,否则为false。
我们要求以下两个属性:
·必须验证有效的签名
verify(pk,message,sign(sk,message))==ture
·签名存在且不可伪造
我们如何使用数字加密技术来搭建它?首先,让我们将以前直观的讨论稍微具体一些。这将使我们更好地理解数字签名方案,并讨论其安全属性。
我们注意到,generateKeys和sign可以是随机算法。事实上,generateeys最好被随机分配,因为它应该为不同的人生成不同的钥匙。另一方面,验证将永远是确定性的。
现在让我们更详细地研究我们要求的数字签名方案的两个属性。第一个属性是直接的——有效的签名必须验证。如果我使用密钥sk签名一个消息,某人稍后尝试使用我的公钥pk验证该签名,该签名必须正确验证。这个属性是签名有用的基本要求。
不可伪造性。第二个要求是伪造的签名在计算上是不可行的。也就是说,一个知道你的公钥并在其他信息上看到你签名的对手不能在没有看到你签名的消息上伪造你的签名。这种不可伪造性的属性通常是以我们与对手一起玩游戏的形式来展现的。在加密安全性证明中,使用游戏是很常见的。
在不可伪造的游戏中,有一个对手声称他可以伪造签名,还有一个挑战者会测试这个声明。我们首先做的是使用generateKeys来生成一个秘密签名密钥和一个相应的公开验证密钥。我们给挑战者提供秘钥,我们把公钥提供给挑战者和对手。所以对手只知道公开的信息,他的使命是试图伪造信息。挑战者知道密钥,所以他可以签名。
直观地,这个游戏的设置符合现实世界的条件。现实生活中的攻击者很可能会看到他们的受害者在许多不同文件上的有效签名。也许攻击者甚至可以操纵受害者签署无害的文件,如果这对攻击者有用。
为了在我们的游戏中建模,我们将允许攻击者在他选择的一些文档上获得签名,只要他想要,只要猜测的数量是合理的。为了直观地了解我们所指的合理猜测数,我们将允许攻击者尝试100万次猜测,而不是2的80次方次猜测。(在渐近的术语中,我们允许攻击者尝试一些密钥大小的多项式的函数的猜测,但没有更多(例如,攻击者无法以指数方式尝试许多猜测)。)
一旦攻击者确信他已经看到足够的签名,那么攻击者会选择一些消息,M,他们将尝试伪造一个签名。对M的唯一限制是它必须是攻击者以前没有看到签名的消息(因为攻击者显然可以发回他被给予的签名!)。挑战者运行验证算法,以确定攻击者生成的签名是否是公共验证密钥下的M上的有效签名。 如果成功验证,攻击者将赢得比赛。
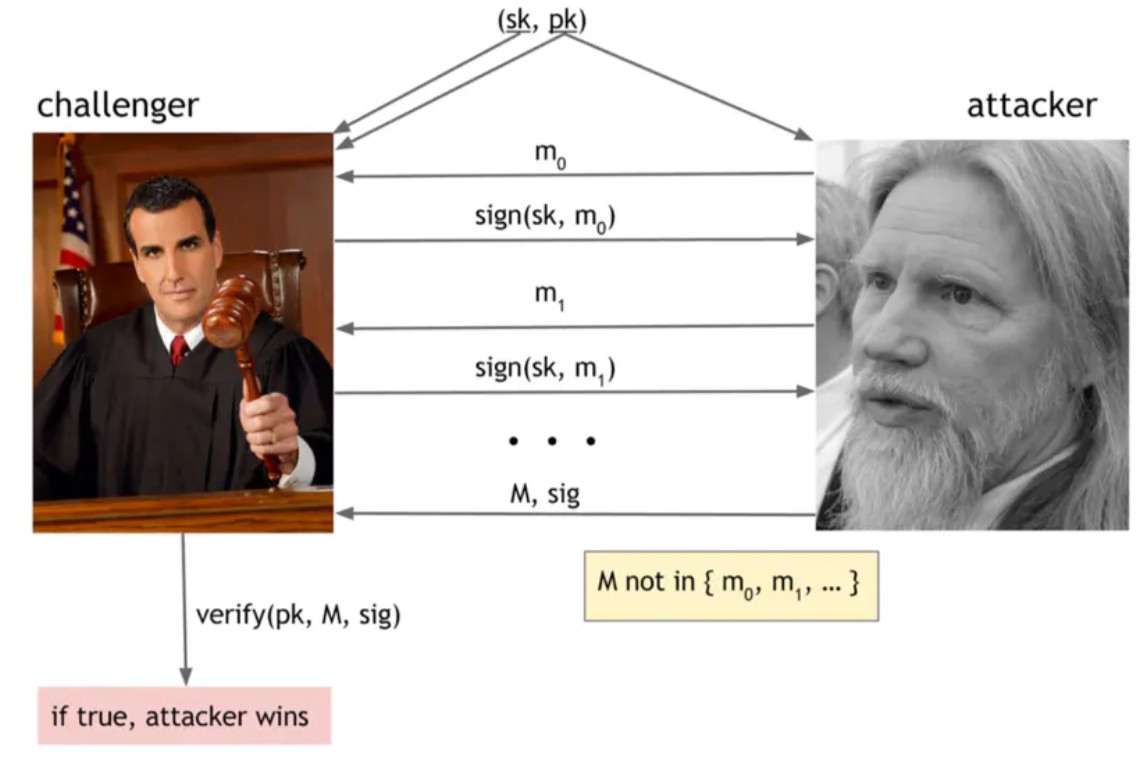
图1.9不可伪造的游戏对手和挑战者玩不可伪造的游戏。 如果攻击者能够在他以前没有看到的消息上成功输出一个签名,他就胜出了。如果他不能,挑战者胜利,则数字签名计划是不可伪造的。
我们认为,当且仅当对手无论对手使用什么算法时,签名方案都是不可伪造的,他成功伪造信息的机会非常小——这么小,以至于我们可以假定它在实践中永远不会发生。
实际问题。有一些实际的事情,我们需要做的是将算法思想变成可以在实践中实现的数字签名机制。例如,许多签名算法是随机的(特别是比特币中使用的),因此我们需要一个很好的随机源。这个真正的重要性不能低估,因为不好的随机性将使您的否则安全的算法不安全。
另一个实际的问题是消息大小。实际上,您可以签署的邮件大小有一个限制,因为实际的方案将在有限长度的位串上运行。有一个简单的方法来解决这个限制:签名消息的哈希,而不是消息本身。如果我们使用具有256位输出的加密哈希函数,那么只要我们的签名方案可以签署256位消息,我们就可以有效地签名任何长度的消息。如前所述,由于哈希函数具有抗冲突性,所以以这种方式将消息的哈希作为消息摘要是安全的。
稍后我们将使用的另一个技巧是你可以签署哈希指针。如果您签署了一个哈希指针,那么签名将覆盖或保护整个结构——而不仅仅是哈希指针本身,而是哈希指针链所指向的一切。例如,如果你要在区块链结尾签署哈希指针,则结果是你将有效地对该整个块链进行数字签名。
ECDSA。现在让我们进入坚果和螺栓。比特币使用一种称为椭圆曲线数字签名算法(ECDSA)的特定数字签名方案。ECDSA是美国政府标准,更新了适用于使用椭圆曲线的早期DSA算法。这些算法多年来已经得到了相当多的加密分析,并且通常被认为是安全的。
更具体地说,比特币在标准椭圆曲线“secp256k1”上使用了ECDSA,该曲线被估计为128以提供128位的安全性(即,像执行2个对称密钥加密操作(如调用哈希函数)一样难以打破此算法)。虽然这个曲线是一个已发布的标准,但它很少在比特币之外使用,其他使用ECDSA的应用程序(如用于安全网页浏览的TLS中的密钥交换)通常使用更常见的“secp256r1”曲线。这只是Bitcoin的一个怪癖,因为Satoshi在系统的早期规范中选中,现在很难改变。
我们不会详细介绍ECDSA的工作原理,因为涉及到一些复杂的数学问题,理解这本书并不必需了解它。如果你对细节感兴趣,请参阅本章末尾的进一步阅读部分。但是,对于各种数量的大小有个了解,这可能是有用的:
Private key: 256bit
Public key, uncompressed: 512bit
Public key, compressed: 257bit
Message to be signed: 256bit
Signature:512bit
请注意,虽然ECDSA技术上只能在256位长的时间内签署消息,但这并不是一个问题:消息在被签名前总是散列,因此可有效地对任何大小的消息进行有效的签名。
使用ECDSA,一个很好的随机来源是至关重要的,因为一个坏的随机源可能会泄露你的钥匙。直观地说,如果您在生成密钥时使用不良随机,则生成的密钥可能不会安全。但是,ECDSA(对于那些熟悉DSA的人来说,这是DSA中的一个普遍现象,而不是椭圆曲线变体独有的)的一个奇怪之处在于,即使你只在签名时使用不良随机,使用完美的钥匙,也会泄露您的私钥。然后是游戏结束;如果你泄露你的私钥,对手可以伪造你的签名。因此,我们需要特别小心在实践中使用良好的随机性,使用不良随机源是其他安全系统的常见缺陷。
边栏:加密货币和加密。 如果你一直在等待Bitcoin中使用哪种加密算法,抱歉让你失望了。如我们看到的,Bitcoin没有加密,因为没有什么需要加密的。加密只是现代加密技术成为可能的一套丰富的技术之一。他们中的许多,比如承诺方案,都会以某种方式隐藏信息,但他们与加密不同。
自此,完成了我们对加密原语数字签名的讨论。在下一节中,我们将讨论数字签名的一些应用,这将被用于构建加密货币。
1.4公钥作为身份
我们来看看一个与数字签名相伴的好招。这个想法是把一个公钥,一个数字签名方案中的公开验证密钥之一,等同于系统中一个人或一个演员的身份。如果你看到一个带有签名的消息在一个公共密钥PK下正确地验证,那么你可以想象成pk在说这则消息。你可以将一个公钥看作一个演员,或一个系统中可以通过签署这些声明来发表声明的一个派对。从这个角度来说,公钥是一种身份。为了让某人为身份pk证明,他们必须知道相应的秘密密钥sk。
将公钥作为身份处理的结果是,您可以随时创建一个新的身份——你只需创建一个新的密钥对,SK和PK,通过generatekeys运行在我们的数字签名方案。pk是您可以使用的新公开身份,而sk是相应的秘密密钥,只有您知道,并允许您代表身份pk发言。因为公钥很大,你可以使用pk的哈希作为你的身份。 如果你这样做,那么为了验证一个消息是否来自你的身份,我们必须检查(1)该pk确实混编了你的身份,(2)该消息在公钥pk下验证。
此外,默认情况下,你的公钥基本上看起来是随机的,没有人能够通过检查pk(当然,一旦你开始使用这个身份进行陈述,这些陈述可能会泄漏信息,让人们可以将pk连接到你的真实世界身份。我们将在稍后进行详细讨论。)来发现你的真实世界身份。 你可以产生一个看起来很随机的新鲜身份,看起来像人群中的脸,只有你可以控制。
分权身份管理。这给我们带来了分权身份管理的想法。你可以为你自己注册一个用户,而不是搭建一个中央集权的机构,以便在这系统中注册为用户。你不需要发布用户名,也不需要通知某人你将要使用特定的名称。如果你想要一个新的身份,你可以随时生成一个,想要多少有多少。如果你喜欢被五个不同的名字所知,没问题!只要做五个身份。如果你想在某一段时间匿名,你可以创建一个新的身份,使用一段时间后把它丢弃。所有这些都可以通过分权身份管理来实现,而事实上,比特币也是这样做的。这些身份在比特币术语中被称为地址。你会经常在上下文中听到Bitcoin和加密币中使用术语地址,这只是一个公钥的哈希值。作为这种分权式身份管理计划的一部分,这是一种凭空形成的身份。
边栏:如果没有中央授权,你可以产生一个身份的想法似乎是违反直觉的。毕竟,如果有人幸运与你产生了相同的密钥,他们能窃取你的比特币吗?
答案是,别人生成相同的256位密钥的可能性太小了,我们在实践中就不用担心了。我们所有的意图和目的都保证这永远不会发生。
更普遍的是,与初学者的直觉相比,概率系统是难以理解且不可预知的,往往是相反的——统计理论允许我们精确量化我们感兴趣的事件的机会,并自信地断言这种系统的行为。
但有一个微妙之处:只有当密钥是随机生成的时候,概率保证才是真的。随机性的产生通常是实际系统中薄弱的一个环节。如果两个用户的计算机使用相同的随机来源或者使用可预测的随机性,则理论保证不再适用。所以在生成密钥时要使用一个很好的随机源,来确保实际的保证与理论上的匹配是至关重要的。
乍一看,分权身份管理可能会导致很大的匿名性和隐私性。毕竟,你可以自己创建一个随机的身份,而不是告诉任何人你的真实身份。但这并不那么简单。随着时间的推移,你创建的身份会产生一系列陈述。人们看到这些陈述,因此知道拥有这个身份的人做了一系列的行动。他们可以开始连接点,使用这一系列的动作来推断关于你真实身份的事情。一个观察者可以随着时间的推移将这些东西联系在一起,并作出推论,导致他们得出结论,如“哎,这个人的行为很像乔。也许这个人是乔。”
换句话说,在比特币的世界你不需要明确地登记或揭示你的真实身份,但你的行为模式本身可能就是识别。这是一个如比特币一样的加密货币的基本隐私问题,实际上我们将把第6章整体付诸实践它。
1.5简单的密码学
现在我们从密码学转移到加密货币。吃我们的加密蔬菜将开始在这里付清,我们将逐渐看到这些片段如何合并在一起,为什么加密操作如哈希函数和数字签名实际上是有用的。在本节中,我们将讨论两种非常简单的加密货币。当然,这需要本书剩下的大部分内容来详细讲解Bitcoin本身是如何运作的含义。
GoofyCoin
第一个是GoofyCoin,它是关于我们可以想象的最简单的加密机制。GoofyCoin只有两个规则。第一个规则是,指定的实体、愚人,都可以创造新的硬币,只要他想要,这些新创造的硬币都属于他。
为了创建一个硬币,Goofy生成一个独特的硬币ID uniqueCoinID,他以前从未生成过,并构造了字符串“CreateCoin [uniqueCoinID]”。然后他用他的秘密签名钥匙计算这个字符串的数字签名。该字符串与Goofy的签名一起,是一枚硬币。任何人都可以验证包含Goofy有效签名的CreateCoin语句的硬币,因此它是有效的硬币。
GoofyCoin的第二条规则是,拥有硬币的人可以将其转让给其他人。 转移硬币不仅仅是将硬币的数据结构发送给收件人——它是使用加密操作来完成的。
让我们说,Goofy想把他创造的硬币转给Alice。为了做到这一点,他创建了一个新的声明,说“付给Alice”,其中“这”是一个哈希指针,引用了所讨论的硬币。正如我们先前所看到的那样,身份确实只是公钥,所以“Alice”是指Alice的公钥。最后,Goofy签署代表该声明的字符串。由于Goofy是最初拥有该硬币的人,他必须签署任何花费硬币的交易。一旦代表Goofy的这笔交易签署的数据结构存在,Alice就拥有这个硬币。她可以向任何人证明她拥有硬币,因为她可以用Goofy的有效签名来提供数据结构。此外,它指向由Goofy拥有的有效硬币。 所以硬币的有效性和所有权在系统中是不言而喻的。
一旦Alice拥有硬币,她可以轮流使用。为了做到这一点,她创造一个声明,说:“把这个硬币付给Bob的公钥”,其中“这”是一个哈希指针,指向由她拥有的硬币。当然,Alice签署了这声明。当任何人提供这个硬币时,都可以验证Bob是业主。他们将跟随哈希指针链回到硬币的创建,并验证每一步,合法的所有者签署一个声明说“把这个硬币付给[新主人]”。
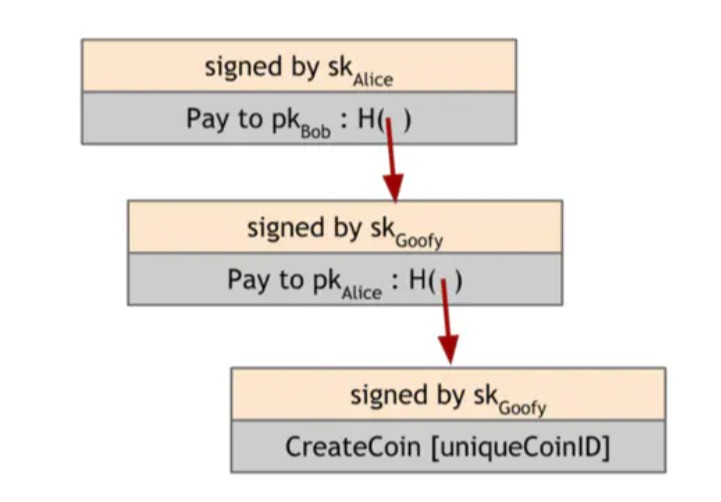
图1.10 GoofyCoin货币 这里展示的是一个硬币(底层),花了两次(中间和顶部)
总而言之,GoofyCoin的规则是:
·Goofy可以通过简单地签署声明来创建新的硬纸,且他创造的新硬币拥有唯一的硬币ID
··拥有硬币的人可以通过签署一份声明“将此硬币兑换给X”(X指定为公钥)的声明将其传递给其他人员
·任何人都可以通过跟随哈希指针链回到Goofy的创建,验证一路上所有的签名,来证明硬币的有效性
当然,GoofyCoin有一个基本的安全问题。让我们说,Alice把她的硬币交给了Bob,同时把签名的声明发送给Bob,但没有告诉任何人。她可以创建另一个签名的声明,向查克支付相同的硬币。对于查克来说,似乎是完美有效的交易,现在他是硬币的所有者。Bob和查克都有有效的索赔声称是这个硬币的所有者。这被称为双花攻击——Alice花费同一枚硬币两次。直观地,我们知道硬币不应该这样工作。
事实上,双花攻击是任何一个密码学必须解决的关键问题之一。GoofyCoin并没有解决双重支出攻击,因此不安全。GoofyCoin是简单的,它的转移机制实际上与比特币非常类似,但是因为它是不安全的,我们不会把它作为一个加密货币。
ScroogeCoin
为了解决双花问题,我们将设计另一种加密货币,我们称之为ScroogeCoin。ScroogeCoin是由GoofyCoin构建的,但在数据结构方面却有点复杂。
第一个关键想法是,一个称为Scrooge的指定实体只发布一个包含所有发生过的历史交易记录的分类账。附加属性确保写入此分类帐的任何数据将永远保留。如果分类帐是唯一的,我们可以使用它来防止双花问题,通过要求所有交易在被接受之前都写入分类帐。这样,如果硬币以前被发送到不同的所有者,它将公开可见。
为了实现这个附加功能,Scrooge可以构建一个区块链(我们之前讨论的数据结构),他将进行数字签名。它是一系列数据块,每个数据块都有一个交易(实际上,作为优化,我们真的把多个交易放在同一个区块中,像Bitcoin那样)。每一个区块都有交易的ID、交易的内容以及前一个区块的哈希指针。Scrooge对最终的哈希指针进行数字签名,该指针将绑定整个结构中的所有数据,并将与该区块链一起发布签名。
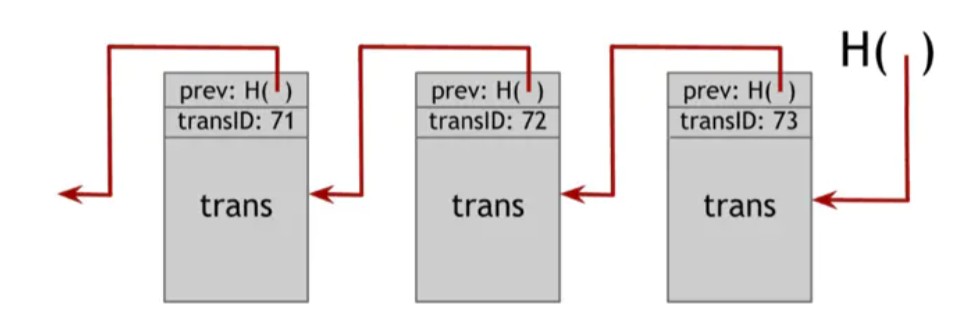
图1.11 ScroogeCoin区块链
在ScroogeCoin中,只计算在Scrooge签署的区块链中的交易。任何人都可以通过检查Scrooge在其出现的区块上的签名来验证交易是否被Scrooge认可。Scrooge确保他不支持一个试图双重支付一个已经交易的硬币的交易。
为什么我们需要一个带有哈希指针的区块链,除了每个区块都有Scrooge的签名?这确保了附加属性。如果Scrooge尝试向历史记录添加或删除交易,或更改现有交易,由于哈希指针,它将影响所有下面的区块。只要有人正在监控Scrooge发布的最新哈希指针,这个变化将是显而易见的。在一个Scrooge单独签名的系统中,您必须跟踪Scrooge发行的每个签名。区块链使得任何两个人都很容易验证他们是否观察到与Scrooge签署的完全相同的历史交易记录。
在ScroogeCoin中,有两种交易。第一种是CreateCoins,就像操作者Goofy可以在GoofyCoin中做一个新的硬币一样。在ScroogeCoin中,我们将扩展语义,以允许在一个交易中创建多个硬币。
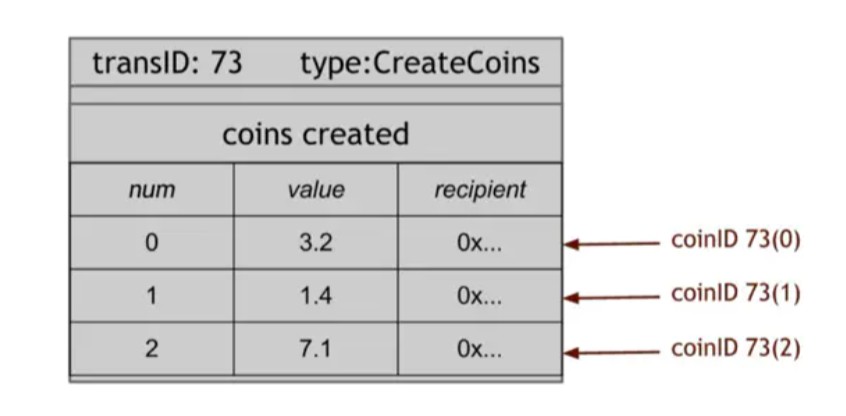
图1.12 CreateCoins交易此CreateCoins交易创建多个硬币。每个硬币在交易中都有一个序列号。每枚硬币也有价值;它值一定数量的ScroogeCoins。最后,每个硬币都有一个收件人,它是创建时获得硬币的公钥。所以CreateCoins创建一堆不同价值的新硬币,并将它们分配给作为初始所有者的人。我们指的是CoinIDs的硬币。一个CoinID是一个交易中该交易ID和硬币序列号的组合。
如果由Scrooge签名,一笔CreateCoins交易总是有效的。我们不用担心Scrooge什么时候有权创造硬币或创造多少,就像我们没有担心在GoofyCoin中,Goofy是如何被选为允许创建硬币的实体。
第二种交易是PayCoins。它消耗一些硬币,也就是销毁它们,并创建相同总价值的新硬币。新的硬币可能属于不同的人(公钥)。这笔交易必须由所有付钱的人签字。因此,如果你是这笔交易中将要使用该硬币的所有者之一,那么你需要对这笔交易进行数字签名,以表明这枚硬币真的很好用。
ScroogeCoin的规则说,如果下面四件事情是真实的,PayCoins的交易则是有效的:
··消费的硬币是有效的,也就是说它们是在以前的交易中创建的。
·消费的硬币在以前的交易中没有被消耗掉。也就是说这不是双重支付。
·从这笔交易中出来的硬币总价值等于流入的硬币总价值。也就是说,只有Scrooge可以创造新的价值。
·交易由所有消费硬币的所有者有效签署。
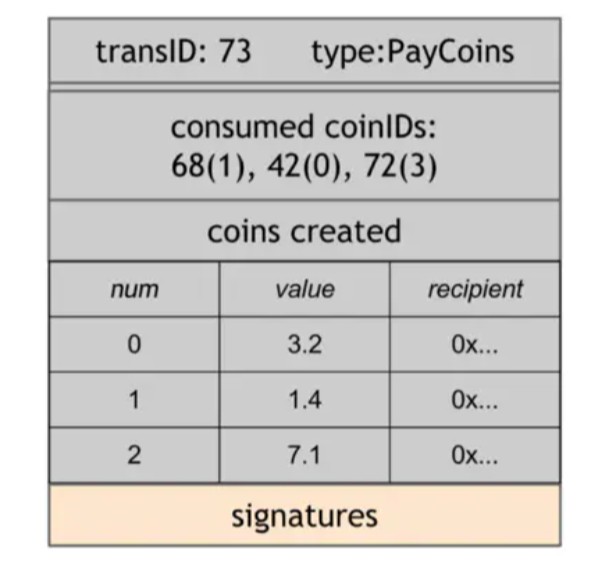
图1.13一个PayCoins的交易
如果满足所有这些条件,则此PayCoins交易有效,Scrooge将会接受。他会将其写入历史,附加到区块链中,之后每个人都可以看到这个交易发生了。只有在这一点上,参与者可以接受交易实际发生了。直到它发布,即使前三个条件有效,它也可能被双重支出交易抢占。
这个系统中的硬币是不可变的——它们永远不会改变、细分或组合。每个硬币在一次交易中创建一次,然后在某些其他交易中被消耗。但是,通过使用交易,我们可以获得与细分或组合硬币相同的效果。例如,为了细分硬币,Alice创建一个新的交易来消耗那个硬币,然后生产两个相同总价值的新硬币。这两个新的硬币可以分配给她。所以尽管硬币在这个系统中是不可变的,但它具有那些不一成不变的硬币系统的全部灵活性。
现在,我们来到ScroogeCoin的核心问题。ScroogeCoin将会以这种意义工作,人们可以看到哪些硬币是有效的。它可以防止双重支出,因为每个人都可以查看区块链,并看到所有的交易都是有效的,且每个硬币只消耗一次。但问题是Scrooge——他的影响力太大。他不能伪造交易,因为他不能伪造别人的签名。但他可以停止批准一些用户的交易,否认他们的服务,使他们的硬币不可用。如果Scrooge是贪婪的(正如他的同名漫画暗示的),他可以拒绝发布交易,除非他们向他转移了一些授权的交易费用。当然,Scrooge也可以为自己创造尽可能多的新硬币。或者Scrooge可能会厌倦整个系统,并全然停止更新区块链。
这里的问题是集权。虽然Scrooge对这个系统很满意,但作为用户,我们可能不会这样做。虽然ScroogeCoin似乎是一个不切实际的建议,但早期对密码系统的研究假定,那里确实会有一些中央信任机构,通常是银行。毕竟,大多数真实世界货币确实有一个值得信赖的发行人(通常是政府造币厂),负责创建货币并确定哪些票据是有效的。然而,有中央机关的加密货币在实践中基本上没有起飞。这有很多原因,但事后看来,很难让人们接受中央授权的加密机制。
因此,我们需要解决的中心技术挑战是,为了改进ScroogeCoin并创建一个可行的系统:我们的系统可以不吝啬吗?也就是我们可以摆脱那个集中的数字吝啬鬼吗?我们可以在许多方面拥有像ScroogeCoin一样运行的加密机制,但没有任何中央信任机构吗?
要做到这一点,我们需要弄清楚所有用户如何就一个已发布的块链达成一致,因为这些交易的历史已经发生了。他们必须一致同意哪些交易是有效的,哪些交易是实际发生的。他们还需要能够以分散的方式将ID分配给事物。最后,新铸造的硬币需要以分散的方式(分布式)进行控制。如果我们可以解决所有这些问题,那么我们可以建立一个像ScroogeCoin这样的货币,但是没有一个集权机构(去中心化)。事实上,这将是一个非常像比特币的系统。
进一步阅读
史提芬.列维的加密是一个非常有趣的,以非技术的眼光看现代密码学的发展和背后的人:
Levy,Steven. C rypto: How the Code Rebels Beat the Government‐‐Saving Privacy in theDigital Age. Penguin, 2001.
列维.巴斯比鲁.史提芬:代码叛军如何击败政府——在数字时代保护隐私.企鹅,2001
现代密码学是一个相当理论的领域。密码学家使用数学来定义原语、协议,以正式的方式获得他们所期待的安全属性,并基于广泛接受的关于特定数学任务的计算硬度的假设来证明他们是安全的。在本章中,我们使用直观的语言来讨论哈希函数和数字签名。对于有兴趣以更为数学的方式和更详细的方式探索这些和其他加密概念的读者,我们建议你参考:
Katz,Jonathan, and Yehuda Lindell. Introduction to Modern Cryptography, SecondEdition. CRC Press, 2014.
Katz,Jonathan和Yehuda Lindell。 现代密码学导论,第二版。CRC Press,2014。
有关应用密码学的介绍,请参阅:
Ferguson,Niels, Bruce Schneier, and Tadayoshi Kohno. Cryptography engineering: designprinciples and practical applications.John Wiley & Sons,2012 .
弗格森,尼尔斯,布鲁斯施奈尔和大田孝如。密码学工程:设计原理和实际应用。约翰·威利父子,2012。
使用SHA-2定义的NIST标准是获取直观加密标准的好方法。
FIPS PUB 180‐4,Secure HashStandards,Federal Information Processing Standards Publication. InformationTechnology Laboratory, National Institute of Standards and Technology,Gaithersburg, MD, 2008.
FIPS PUB 180-4,安全哈希标准,联邦信息处理标准出版物。 信息技术实验室,国家标准与技术研究所,Gaithersburg,MD,2008。
最后,这是描述ECDSA签名算法的标准化版本论文。
Johnson,Don, Alfred Menezes, and Scott Vanstone. The elliptic curve digital signaturealgorithm (ECDSA). International Journal of Information Security 1.1 (2001):36‐63.
约翰逊,唐,阿尔弗雷德·梅内塞斯和斯科特·范斯通。 椭圆曲线数字签名算法(ECDSA)。 国际信息安全杂志1.1(2001):36-63。
